Some catastrophe models compensate for the inadequacies of two parameter severity distributions by including point weights at zero and total loss. These are generally undocumented but appear to be non-zero values of probability density corresponding to mean damage ratios of zero and unity. The severity distribution between zero and unity is invariably represented by a two parameter probability distribution. Therefore, at least theoretically, we have a four parameter severity distribution.
At the time of writing these parameters are not well documented but can be inferred as described below.
For a single event, the general form for the calculation of “gross” expected loss net of deductible D and limit L is:
this is true for both continuous and discrete forms of the original (or “ground up”) severity distribution P(x). Considering two different limits, L1 and L2, on the same ground up distribution, we can say that
if both cases have no deductible. As L1 → L2, we can say that P(x>L1) → P(x>L2) so that
assuming that
which should certainly be true in the case where we have a significant probability density at x = 1. If we know we have a significant point weight corresponding to total loss, we can infer that point weight by comparing ground up (GU) and gross (GR) expected losses considering a limit L close to the insured value T:
This post explores the shape of Beta distributions typically used to represent original (“ground up” or damage) loss distributions in commercial catastrophe models.
The shape parameters of the Beta distribution, A and B, must be both positive and real. This places some constraints on the values of expected loss (µ) and standard deviation (σ) which can be represented with a beta distribution. Part 1 describes how the shape parameter A can be expressed as a function of µ and σ. Constraining A > 0 it is simple to show that:
where C represents the coefficient of variation; the ratio of standard deviation to expected loss. It follows that the second shape parameter, B, also satisfies the constraint because 0 < µ < 1 is always true.
The same approach shows that A < 1 results when:
and A > 1 when:
(Note that C is constrained to be <1 whenever A>1)
Similarly, it is simple to show that B < 1 where:
and therefore where:
Finally, B > 1 where:
Plotting contours of these C(µ) relationships results in the following graph:
1. Linear-log contour plot of C(µ) for shape parameters near 0 and 1
These contours demark the four basic shapes of the beta distribution as described in Part 2. Replotting this graph as linear-log distorts the plot but allows the four basic shapes of the distribution to be shown within these contours:
2. Log-linear plot of C(µ) contours demarking the 4 basic shapes of the beta distribution
Unsurprisingly this blog does not itself hold a licence for any of the commercial vendor models, so data from the model vendors will not be shown. Nonetheless, any reader with access to a vendor model is invited to explore location- or risk-level C(µ) relationships in their models. This is easy to do: simply report expected loss and standard deviation per event for a single, geocoded location referencing a single vulnerability function.
An empirical observation is that original damage relationships never fall in the range where the beta distribution B parameter takes a value <1. This appears to be true for all perils, all geographies and all vendors (even those that do not model original loss severity with a beta distribution).
Part 2 established that (1) the beta distribution can only approximate total losses and (2) this only occurs when the B shape parameter is less than unity. In other words, even at location level, those commercial models using beta distributions don’t even approximate total loss to a location.
Again, this bears repeating. Those models which use a beta distribution to model loss severity do not consider total loss. Moreover, they do not even approximate total loss.
(It is also worth noting that – even under perfect correlation of standard deviations – C cannot increase as location loss distributions are combined. Therefore, it is not possible for any aggregate loss distribution approximate total loss).
Beta distributions appear everywhere in catastrophe modelling. At least, they appear more often than not when a vendor is trying to represent uncertainty in loss severity. This is odd, considering how rarely this distribution is used in other actuarial or engineering disciplines. Nonetheless, all of the major catastrophe model vendors use Beta distributions somewhere in their financial engines; and one or two even use the Beta distribution exclusively.
The most common justification for using the Beta distribution is its ability to assume many forms. It is, of course, reasonable to wonder whether a distribution capable of assuming so many different forms can represent any physical reality. There is also a more pragmatic explanation; a distribution naturally bounded by zero and unity doesn’t need artificial truncation to avoid (a) negative loss or (b) losses greater than the sum insured.
The PDF has four basic shapes, depending on the values of the (positive, real) shape parameters A and B described in Part 1. The following four figures show the basic shape of the distribution for the four cases where each parameter can take values less than or greater than unity.
(Note, in the case of either shape parameter taking a value of 1 a power law distribution results. If both shape parameters are unity, the PDF is also unity for all values of x.)
Case 1: both shape parameters < 1Case 2: A < 1; B > 1Case 3: A > 1; B < 1Case 4: both shape parameters > 1
The first thing to observe is that in all cases, the probability of both zero loss and total loss is zero. In other words, wherever a Beta distribution is being used to model loss severity, neither zero loss nor total loss are considered. This becomes evident when the PDF formula in Part 1 is examined.
This is worth repeating. Whenever a Beta distribution is used to represent loss severity, total loss is not possible. Similarly, there is no possibility of zero loss. This is not unreasonable when modelling losses to aggregates. However, this is – at very best – questionable when modelling losses to individual properties (i.e. using “detailed” data).
It could be argued that cases 1 and 2 appear to make a reasonable approximation of representing zero loss; and cases 1 and 3 appear to do the same for total loss. It is therefore instructive to look at the circumstances under which the original (“ground up” or “damage”) distribution could assume each of these shapes. This will be explored in the next post on Beta distributions.
(Note, the application of non-proportional financial terms such as excess points and first loss limits introduces more parameters and further complicates the general description made here. For this reason original loss distributions will be investigated)
In geophysical catastrophe modelling, the Beta distribution is the most popular probability distribution used to describe uncertainty in loss severity. The distribution is a continuous two-parameter function bounded by values of zero and unity.
The PDF of the Beta distribution is a function of its two shape parameters A and B:
β(A,B) simply normalises the distribution and is given by
The expected loss of the distribution is given by:
and its variance by:
In catastrophe modelling applications it is normal to want to derive the shape parameters from an expected loss and its standard deviation. A little work shows us that
Note, the distribution is evaluated on values of x bounded by 0 and 1. In catastrophe modelling applications, the expected loss μ is represented by the ratio of the expected loss to the sum insured (or limit, or “exposed value”)







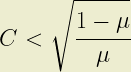
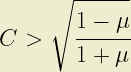



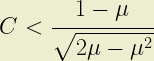






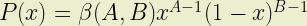

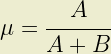
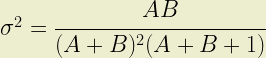
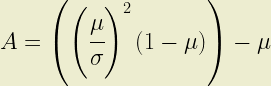
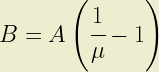
You must be logged in to post a comment.