

This post explores the shape of Beta distributions typically used to represent original (“ground up” or damage) loss distributions in commercial catastrophe models.
The shape parameters of the Beta distribution, A and B, must be both positive and real. This places some constraints on the values of expected loss (µ) and standard deviation (σ) which can be represented with a beta distribution. Part 1 describes how the shape parameter A can be expressed as a function of µ and σ. Constraining A > 0 it is simple to show that:
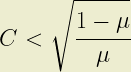
where C represents the coefficient of variation; the ratio of standard deviation to expected loss. It follows that the second shape parameter, B, also satisfies the constraint because 0 < µ < 1 is always true.
The same approach shows that A < 1 results when:
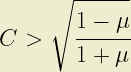
and A > 1 when:

(Note that C is constrained to be <1 whenever A>1)
Similarly, it is simple to show that B < 1 where:

and therefore where:

Finally, B > 1 where:
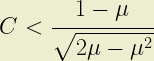
Plotting contours of these C(µ) relationships results in the following graph:

These contours demark the four basic shapes of the beta distribution as described in Part 2. Replotting this graph as linear-log distorts the plot but allows the four basic shapes of the distribution to be shown within these contours:

Unsurprisingly this blog does not itself hold a licence for any of the commercial vendor models, so data from the model vendors will not be shown. Nonetheless, any reader with access to a vendor model is invited to explore location- or risk-level C(µ) relationships in their models. This is easy to do: simply report expected loss and standard deviation per event for a single, geocoded location referencing a single vulnerability function.
An empirical observation is that original damage relationships never fall in the range where the beta distribution B parameter takes a value <1. This appears to be true for all perils, all geographies and all vendors (even those that do not model original loss severity with a beta distribution).
Part 2 established that (1) the beta distribution can only approximate total losses and (2) this only occurs when the B shape parameter is less than unity. In other words, even at location level, those commercial models using beta distributions don’t even approximate total loss to a location.
Again, this bears repeating. Those models which use a beta distribution to model loss severity do not consider total loss. Moreover, they do not even approximate total loss.
(It is also worth noting that – even under perfect correlation of standard deviations – C cannot increase as location loss distributions are combined. Therefore, it is not possible for any aggregate loss distribution approximate total loss).





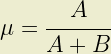
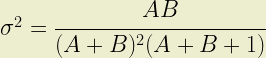
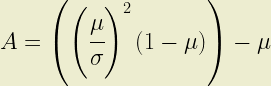
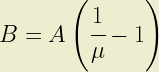




You must be logged in to post a comment.